100 % auditable, de l'ingestion à la réponse
La transparence n'est pas une option : chaque maillon de la chaîne est contrôlé et explicable.
Extraction de l'information, disponible à 100 %
FIREBOT repose sur la technologie RAG. À l'ingestion d'un document dans la base de connaissance, chaque image, tableau et diagramme est analysé spécifiquement. La structure hiérarchique est extraite et préservée, pour que chaque segment d'information soit autosuffisant, homogène et relié au reste de l'information déjà en base.
Cette approche de l'extraction et de l'organisation de l'information — à mi-chemin entre le Contextual Retrieval (contexte ajouté à chaque passage, Anthropic) et l'optimisation de la stratégie de découpage (façon Vectorize) — est le socle qui permet d'atteindre des performances de recherche supérieures à 95 %.
Contrairement à tous les systèmes du marché, la totalité de votre document se retrouve en base, propre.
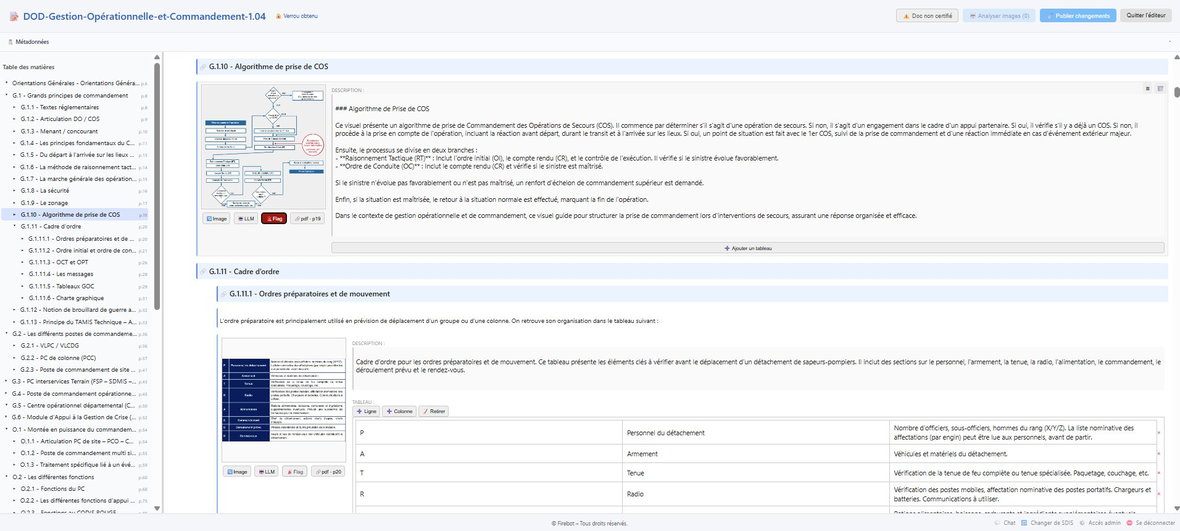
Base de données transparente à 100 %
Après extraction, un éditeur permet de visualiser l'extraction et de corriger manuellement la totalité du document et de sa structure. Images, tableaux, textes et structures peuvent être édités par les administrateurs pour garantir une information 100 % juste en base.
Contrairement à tous les systèmes du marché, vous voyez ce que l'IA voit.
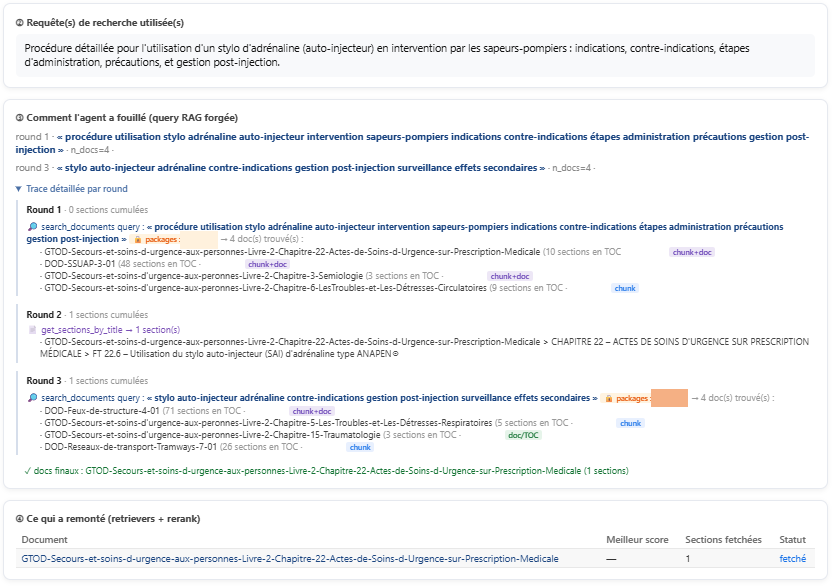
Chaîne IA transparente à 100 %
FIREBOT a développé un agent de recherche doté d'outils pour naviguer dans vos bibliothèques de documents avec une double approche — humaine : recherche de documents, lecture de la table des matières, navigation dans le document, lecture de section ; et informatique : recherche de sections par mots-clés (BM25), recherche de contenu par similarité sémantique, stratégie de reranking.
Contrairement à tous les systèmes du marché, vous avez accès à la totalité de la chaîne de raisonnement de l'IA.
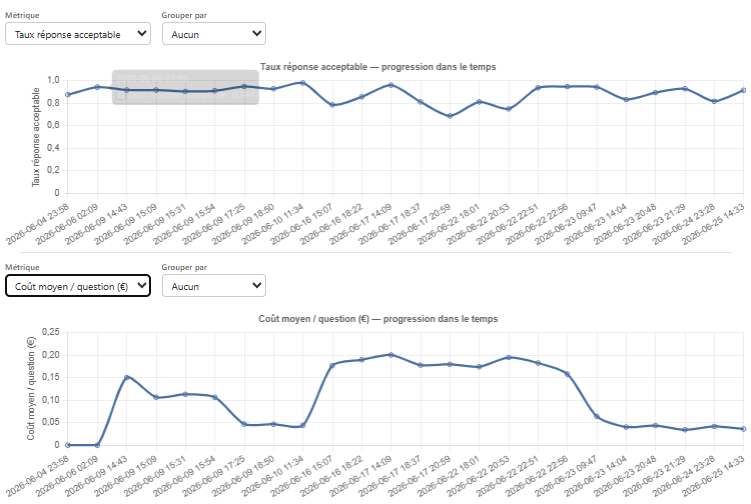
Suivi de performance et qualité
Les administrateurs disposent d'outils d'export et de mesure de la qualité perçue par les utilisateurs (👍 👎). Chaque « pouce en bas » peut être analysé pour identifier si le problème vient d'un document manquant ou d'une erreur de l'IA.
Au-delà de la métrique humaine, FIREBOT permet le développement automatisé de jeux de données de test, qui contrôlent en continu le maintien des performances au fil de l'ajout des documents.
Contrairement à tous les systèmes du marché, un contrôle qualité continu sur VOTRE jeu de données.